
Setup #
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, Subset
import torchvision
import torchvision.transforms as transforms
from torch.cuda.amp import GradScaler, autocast
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import classification_report, confusion_matrix
import random
import time
random.seed(42)
np.random.seed(42)
torch.manual_seed(42)
torch.cuda.manual_seed_all(42)
torch.backends.cudnn.benchmark = True
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Device: {device}")
if device.type == "cuda":
print(f"GPU: {torch.cuda.get_device_name(0)}")
vram_gb = torch.cuda.get_device_properties(0).total_memory / 1e9
print(f"VRAM: {vram_gb:.1f} GB")Device: cuda
GPU: NVIDIA GeForce RTX 3090
VRAM: 25.3 GB
Load Oxford-IIIT Pet #
The Oxford-IIIT Pet dataset has 37 cat and dog breeds with roughly 200 images per class at 200-500px resolution. We cap to 6 classes for a manageable but challenging multi-class problem, resize to 224×224 so pretrained models work at their native resolution, and use ImageNet normalization. We split the trainval portion into 80% training and 20% validation.
NUM_CLASSES = 6
IMG_SIZE = 224
DATA_DIR = "/home/migue/.cache"
BATCH = 64
imagenet_mean = (0.485, 0.456, 0.406)
imagenet_std = (0.229, 0.224, 0.225)
transform_train = transforms.Compose([
transforms.Resize((IMG_SIZE, IMG_SIZE)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(imagenet_mean, imagenet_std),
])
transform_test = transforms.Compose([
transforms.Resize((IMG_SIZE, IMG_SIZE)),
transforms.ToTensor(),
transforms.Normalize(imagenet_mean, imagenet_std),
])
# Load full trainval split, then filter to first 6 classes
full_dataset = torchvision.datasets.OxfordIIITPet(
root=DATA_DIR, split="trainval", target_types="category",
download=True, transform=transform_train,
)
# Collect labels within the dataset
all_labels = [full_dataset[i][1] for i in range(len(full_dataset))]
keep_idx = [i for i, lbl in enumerate(all_labels) if lbl < NUM_CLASSES]
filtered = Subset(full_dataset, keep_idx)
# Build test set with test split, same class filter
test_full = torchvision.datasets.OxfordIIITPet(
root=DATA_DIR, split="test", target_types="category",
download=True, transform=transform_test,
)
test_labels = [test_full[i][1] for i in range(len(test_full))]
test_idx = [i for i, lbl in enumerate(test_labels) if lbl < NUM_CLASSES]
test_set = Subset(test_full, test_idx)
# Train/val split
indices = list(range(len(filtered)))
random.shuffle(indices)
split = int(0.8 * len(indices))
train_set = Subset(filtered, indices[:split])
val_set = Subset(filtered, indices[split:])
train_loader = DataLoader(train_set, batch_size=BATCH, shuffle=True,
pin_memory=True, num_workers=4)
val_loader = DataLoader(val_set, batch_size=BATCH, shuffle=False,
pin_memory=True, num_workers=4)
test_loader = DataLoader(test_set, batch_size=BATCH, shuffle=False,
pin_memory=True, num_workers=4)
classes = ('Abyssinian', 'american_bulldog', 'american_pit_bull',
'basset_hound', 'beagle', 'Bengal')
print(f"Train: {len(train_set)} Val: {len(val_set)} Test: {len(test_set)}")
print(f"Classes: {', '.join(classes)}")Train: 480 Val: 120 Test: 598
Classes: Abyssinian, american_bulldog, american_pit_bull, basset_hound, beagle, Bengal
Explore the Data #
224×224 RGB images at full resolution. The Oxford-IIIT Pet dataset provides real-world photographs with varied backgrounds, poses, and lighting, a much harder benchmark than CIFAR-10.
temp_set = torchvision.datasets.OxfordIIITPet(
root=DATA_DIR, split="trainval", target_types="category",
download=False, transform=transforms.Compose([
transforms.Resize((IMG_SIZE, IMG_SIZE)),
transforms.ToTensor(),
]),
)
temp_labels = [temp_set[i][1] for i in range(len(temp_set))]
temp_idx = [i for i, lbl in enumerate(temp_labels) if lbl < NUM_CLASSES]
temp = Subset(temp_set, temp_idx)
temp_loader = DataLoader(temp, batch_size=16, shuffle=True)
images, labels = next(iter(temp_loader))
fig, axes = plt.subplots(2, 8, figsize=(12, 5))
for ax, img, lbl in zip(axes.flat, images, labels):
ax.imshow(img.permute(1, 2, 0))
ax.set_title(classes[lbl], fontsize=8)
ax.axis("off")
plt.tight_layout()
plt.show()
train_targets = [filtered[i][1] for i in indices[:split]]
counts = [train_targets.count(i) for i in range(NUM_CLASSES)]
fig, ax = plt.subplots(figsize=(8, 4))
bars = ax.bar(classes, counts)
ax.bar_label(bars, fontsize=9)
ax.set_ylabel("Samples")
ax.set_title("Training Set Class Distribution")
plt.xticks(rotation=30, ha="right")
plt.tight_layout()
plt.show()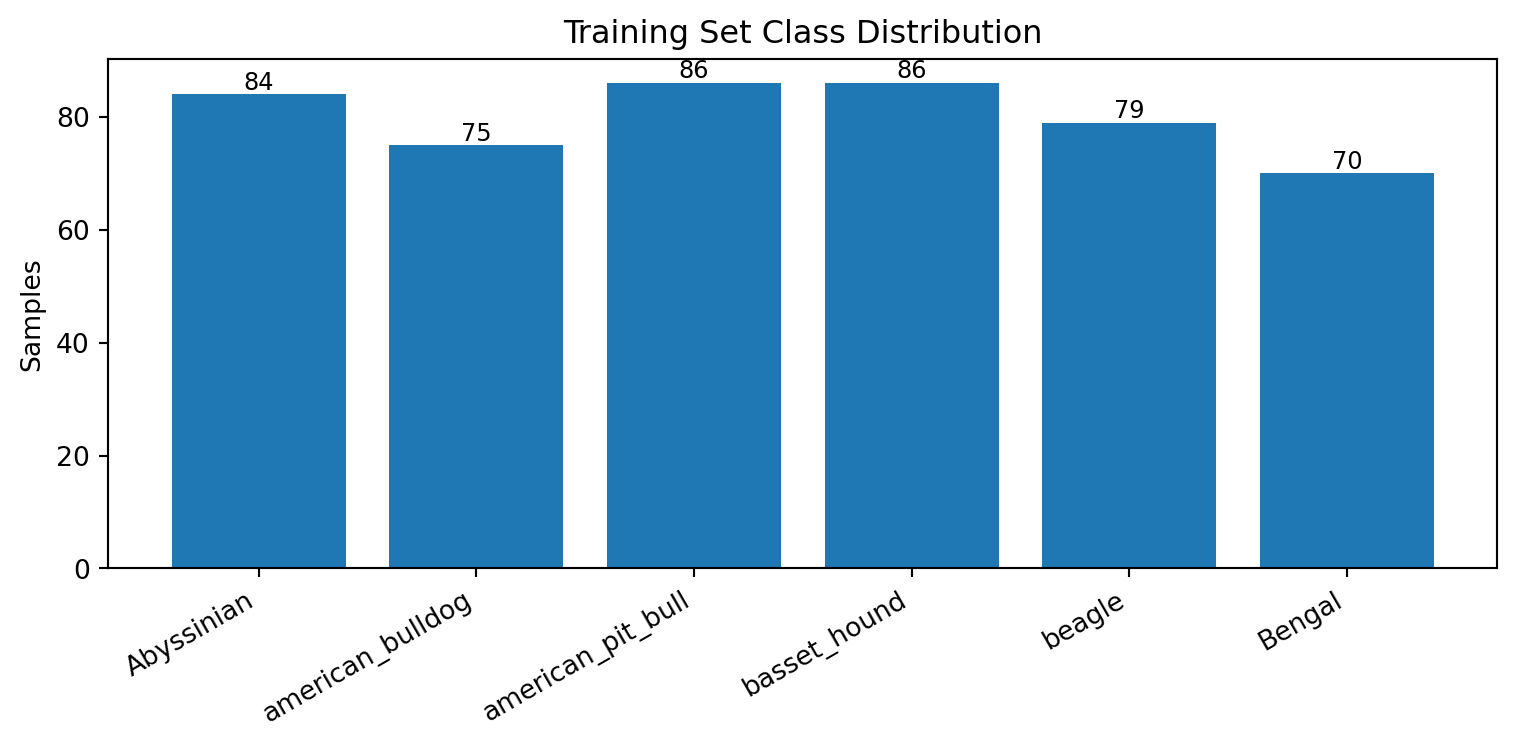
Shared Utilities #
These functions are reused by all our models. train_epoch does one pass with mixed precision. evaluate runs validation or testing. print_architecture displays every layer with its output shape and parameter count. We define the loss once, shared by every model.
def train_epoch(model, loader, criterion, optimizer, scaler):
model.train()
running_loss, correct, total = 0.0, 0, 0
for inputs, targets in loader:
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
with autocast():
outputs = model(inputs)
loss = criterion(outputs, targets)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
running_loss += loss.item()
_, pred = outputs.max(1)
total += targets.size(0)
correct += pred.eq(targets).sum().item()
return running_loss / len(loader), 100.0 * correct / total
@torch.no_grad()
def evaluate(model, loader, criterion):
model.eval()
running_loss, correct, total = 0.0, 0, 0
for inputs, targets in loader:
inputs, targets = inputs.to(device), targets.to(device)
with autocast():
outputs = model(inputs)
loss = criterion(outputs, targets)
running_loss += loss.item()
_, pred = outputs.max(1)
total += targets.size(0)
correct += pred.eq(targets).sum().item()
return running_loss / len(loader), 100.0 * correct / total
def print_architecture(model, input_size=(1, 3, IMG_SIZE, IMG_SIZE)):
x = torch.randn(*input_size).to(device)
model = model.to(device)
model.eval()
print(f"{'Layer':<35} {'Output Shape':<25} {'Params':>10}")
print("=" * 73)
hooks = []
def make_hook(name):
def hook(module, inp, out):
params = sum(p.numel() for p in module.parameters())
shape = str(list(out.shape)) if not isinstance(out, (list, tuple)) else str([list(o.shape) for o in out])
if params > 0 or isinstance(module, (nn.ReLU, nn.MaxPool2d, nn.AdaptiveAvgPool2d, nn.Dropout, nn.Flatten)):
print(f"{name:<35} {shape:<25} {params:>10,}")
return hook
for name, m in model.named_modules():
if not name:
continue
hooks.append(m.register_forward_hook(make_hook(name)))
with torch.no_grad():
_ = model(x)
for h in hooks:
h.remove()
total = sum(p.numel() for p in model.parameters())
print("=" * 73)
print(f"{'Total':<35} {'':<25} {total:>10,}")
return total
criterion = nn.CrossEntropyLoss()Part 1: Plain CNN #
A basic stack of Conv2d + ReLU + MaxPool2d. No BatchNorm, no residual connections, no Dropout. This is our baseline.
class PlainCNN(nn.Module):
def __init__(self, num_classes=NUM_CLASSES):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(32, 64, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(64, 128, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(128, 256, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
)
self.pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(256, num_classes)
def forward(self, x):
x = self.features(x)
x = self.pool(x)
x = x.view(x.size(0), -1)
return self.fc(x)plain = PlainCNN()
print_architecture(plain)Layer Output Shape Params
=========================================================================
features.0 [1, 32, 224, 224] 896
features.1 [1, 32, 224, 224] 0
features.2 [1, 32, 112, 112] 0
features.3 [1, 64, 112, 112] 18,496
features.4 [1, 64, 112, 112] 0
features.5 [1, 64, 56, 56] 0
features.6 [1, 128, 56, 56] 73,856
features.7 [1, 128, 56, 56] 0
features.8 [1, 128, 28, 28] 0
features.9 [1, 256, 28, 28] 295,168
features.10 [1, 256, 28, 28] 0
features.11 [1, 256, 14, 14] 0
features [1, 256, 14, 14] 388,416
pool [1, 256, 1, 1] 0
fc [1, 6] 1,542
=========================================================================
Total 389,958
389958
Channels grow (32→64→128→256) while spatial size shrinks (224→112→56→28→14). The feature pyramid in its simplest form.
plain = PlainCNN().to(device)
opt = torch.optim.AdamW(plain.parameters(), lr=1e-3, weight_decay=1e-4)
sched = torch.optim.lr_scheduler.CosineAnnealingLR(opt, T_max=20)
scaler = GradScaler()
epochs, patience = 20, 10
best_loss, epochs_no_improve = float("inf"), 0
best_acc = 0.0
print(f"PlainCNN, {sum(p.numel() for p in plain.parameters()):,} parameters\n")
for epoch in range(1, epochs + 1):
tl, ta = train_epoch(plain, train_loader, criterion, opt, scaler)
vl, va = evaluate(plain, val_loader, criterion)
sched.step()
if va > best_acc:
best_acc = va
improved = ""
if vl < best_loss:
best_loss = vl
epochs_no_improve = 0
improved = " *"
else:
epochs_no_improve += 1
print(f"Epoch {epoch:2d} | Train Acc {ta:5.2f}% | Val Acc {va:5.2f}%{improved}")
if epochs_no_improve >= patience:
print(f"Early stopping at epoch {epoch}")
break
test_loss, plain_acc = evaluate(plain, test_loader, criterion)
print(f"\nPlainCNN test accuracy: {plain_acc:.2f}% (best val: {best_acc:.1f}%)")PlainCNN, 389,958 parameters
/tmp/ipykernel_26143/3925818616.py:4: FutureWarning: `torch.cuda.amp.GradScaler(args...)` is deprecated. Please use `torch.amp.GradScaler('cuda', args...)` instead.
scaler = GradScaler()
/tmp/ipykernel_26143/2983837481.py:7: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with autocast():
/tmp/ipykernel_26143/2983837481.py:25: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with autocast():
Epoch 1 | Train Acc 18.12% | Val Acc 15.83% *
Epoch 2 | Train Acc 22.29% | Val Acc 15.83%
Epoch 3 | Train Acc 24.79% | Val Acc 18.33% *
Epoch 4 | Train Acc 24.79% | Val Acc 20.83% *
Epoch 5 | Train Acc 27.92% | Val Acc 22.50% *
Epoch 6 | Train Acc 30.00% | Val Acc 25.00%
Epoch 7 | Train Acc 26.88% | Val Acc 23.33%
Epoch 8 | Train Acc 31.04% | Val Acc 25.00%
Epoch 9 | Train Acc 33.33% | Val Acc 25.00%
Epoch 10 | Train Acc 34.17% | Val Acc 26.67%
Epoch 11 | Train Acc 31.88% | Val Acc 27.50% *
Epoch 12 | Train Acc 33.75% | Val Acc 26.67%
Epoch 13 | Train Acc 34.38% | Val Acc 24.17%
Epoch 14 | Train Acc 35.62% | Val Acc 25.00%
Epoch 15 | Train Acc 36.88% | Val Acc 25.83% *
Epoch 16 | Train Acc 38.12% | Val Acc 25.00% *
Epoch 17 | Train Acc 36.67% | Val Acc 25.00% *
Epoch 18 | Train Acc 37.08% | Val Acc 26.67%
Epoch 19 | Train Acc 38.54% | Val Acc 25.00%
Epoch 20 | Train Acc 37.92% | Val Acc 26.67%
PlainCNN test accuracy: 25.08% (best val: 27.5%)
Part 2: PlainCNN + Dropout #
Same architecture, adding nn.Dropout(0.3) before the classifier. Dropout randomly zeros 30% of the feature vector during training, forcing the model to rely on distributed representations.
class PlainCNNDropout(nn.Module):
def __init__(self, num_classes=NUM_CLASSES):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(32, 64, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(64, 128, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(128, 256, 3, padding=1), nn.ReLU(), nn.MaxPool2d(2),
)
self.pool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.3)
self.fc = nn.Linear(256, num_classes)
def forward(self, x):
x = self.features(x)
x = self.pool(x)
x = x.view(x.size(0), -1)
x = self.dropout(x)
x = self.fc(x)
return xdropper = PlainCNNDropout()
print_architecture(dropper)Layer Output Shape Params
=========================================================================
features.0 [1, 32, 224, 224] 896
features.1 [1, 32, 224, 224] 0
features.2 [1, 32, 112, 112] 0
features.3 [1, 64, 112, 112] 18,496
features.4 [1, 64, 112, 112] 0
features.5 [1, 64, 56, 56] 0
features.6 [1, 128, 56, 56] 73,856
features.7 [1, 128, 56, 56] 0
features.8 [1, 128, 28, 28] 0
features.9 [1, 256, 28, 28] 295,168
features.10 [1, 256, 28, 28] 0
features.11 [1, 256, 14, 14] 0
features [1, 256, 14, 14] 388,416
pool [1, 256, 1, 1] 0
dropout [1, 256] 0
fc [1, 6] 1,542
=========================================================================
Total 389,958
389958
Dropout adds zero parameters, it is a free regularizer.
dropper = PlainCNNDropout().to(device)
opt = torch.optim.AdamW(dropper.parameters(), lr=1e-3, weight_decay=1e-4)
sched = torch.optim.lr_scheduler.CosineAnnealingLR(opt, T_max=20)
scaler = GradScaler()
best_loss, epochs_no_improve = float("inf"), 0
best_acc = 0.0
print(f"PlainCNN+Dropout, {sum(p.numel() for p in dropper.parameters()):,} parameters\n")
for epoch in range(1, 21):
tl, ta = train_epoch(dropper, train_loader, criterion, opt, scaler)
vl, va = evaluate(dropper, val_loader, criterion)
sched.step()
if va > best_acc:
best_acc = va
improved = ""
if vl < best_loss:
best_loss = vl
epochs_no_improve = 0
improved = " *"
else:
epochs_no_improve += 1
print(f"Epoch {epoch:2d} | Train Acc {ta:5.2f}% | Val Acc {va:5.2f}%{improved}")
if epochs_no_improve >= 10:
print(f"Early stopping at epoch {epoch}")
break
test_loss, drop_acc = evaluate(dropper, test_loader, criterion)
print(f"\nPlainCNN+Dropout test accuracy: {drop_acc:.2f}% (best val: {best_acc:.1f}%)")
print(f"Improvement over PlainCNN: +{drop_acc - plain_acc:.1f}%")PlainCNN+Dropout, 389,958 parameters
/tmp/ipykernel_26143/2963331684.py:4: FutureWarning: `torch.cuda.amp.GradScaler(args...)` is deprecated. Please use `torch.amp.GradScaler('cuda', args...)` instead.
scaler = GradScaler()
/tmp/ipykernel_26143/2983837481.py:7: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with autocast():
Epoch 1 | Train Acc 18.12% | Val Acc 15.00% *
/tmp/ipykernel_26143/2983837481.py:25: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with autocast():
Epoch 2 | Train Acc 19.79% | Val Acc 15.83%
Epoch 3 | Train Acc 21.04% | Val Acc 15.00% *
Epoch 4 | Train Acc 24.79% | Val Acc 19.17% *
Epoch 5 | Train Acc 27.29% | Val Acc 23.33% *
Epoch 6 | Train Acc 26.04% | Val Acc 20.83%
Epoch 7 | Train Acc 30.21% | Val Acc 24.17% *
Epoch 8 | Train Acc 26.67% | Val Acc 25.83%
Epoch 9 | Train Acc 32.92% | Val Acc 27.50% *
Epoch 10 | Train Acc 28.75% | Val Acc 26.67%
Epoch 11 | Train Acc 34.17% | Val Acc 27.50%
Epoch 12 | Train Acc 31.88% | Val Acc 30.00% *
Epoch 13 | Train Acc 29.79% | Val Acc 25.00%
Epoch 14 | Train Acc 33.75% | Val Acc 30.83%
Epoch 15 | Train Acc 32.08% | Val Acc 29.17%
Epoch 16 | Train Acc 35.21% | Val Acc 25.00%
Epoch 17 | Train Acc 35.62% | Val Acc 28.33%
Epoch 18 | Train Acc 38.33% | Val Acc 29.17%
Epoch 19 | Train Acc 34.38% | Val Acc 30.00%
Epoch 20 | Train Acc 36.25% | Val Acc 29.17%
PlainCNN+Dropout test accuracy: 23.58% (best val: 30.8%)
Improvement over PlainCNN: +-1.5%
Part 3: Adding BatchNorm #
Add BatchNorm2d after every convolution and remove the bias (BatchNorm provides its own shift). This stabilizes training and typically gives a solid accuracy boost.
class CNNBN(nn.Module):
def __init__(self, num_classes=NUM_CLASSES):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, 3, padding=1, bias=False), nn.BatchNorm2d(32),
nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(32, 64, 3, padding=1, bias=False), nn.BatchNorm2d(64),
nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(64, 128, 3, padding=1, bias=False), nn.BatchNorm2d(128),
nn.ReLU(), nn.MaxPool2d(2),
nn.Conv2d(128, 256, 3, padding=1, bias=False), nn.BatchNorm2d(256),
nn.ReLU(), nn.MaxPool2d(2),
)
self.pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(256, num_classes)
def forward(self, x):
x = self.features(x)
x = self.pool(x)
x = x.view(x.size(0), -1)
return self.fc(x)cnn_bn = CNNBN()
print_architecture(cnn_bn)Layer Output Shape Params
=========================================================================
features.0 [1, 32, 224, 224] 864
features.1 [1, 32, 224, 224] 64
features.2 [1, 32, 224, 224] 0
features.3 [1, 32, 112, 112] 0
features.4 [1, 64, 112, 112] 18,432
features.5 [1, 64, 112, 112] 128
features.6 [1, 64, 112, 112] 0
features.7 [1, 64, 56, 56] 0
features.8 [1, 128, 56, 56] 73,728
features.9 [1, 128, 56, 56] 256
features.10 [1, 128, 56, 56] 0
features.11 [1, 128, 28, 28] 0
features.12 [1, 256, 28, 28] 294,912
features.13 [1, 256, 28, 28] 512
features.14 [1, 256, 28, 28] 0
features.15 [1, 256, 14, 14] 0
features [1, 256, 14, 14] 388,896
pool [1, 256, 1, 1] 0
fc [1, 6] 1,542
=========================================================================
Total 390,438
390438
cnn_bn = CNNBN().to(device)
opt = torch.optim.AdamW(cnn_bn.parameters(), lr=1e-3, weight_decay=1e-4)
sched = torch.optim.lr_scheduler.CosineAnnealingLR(opt, T_max=20)
scaler = GradScaler()
best_loss, epochs_no_improve = float("inf"), 0
best_acc = 0.0
print(f"CNN+BN, {sum(p.numel() for p in cnn_bn.parameters()):,} parameters\n")
for epoch in range(1, 21):
tl, ta = train_epoch(cnn_bn, train_loader, criterion, opt, scaler)
vl, va = evaluate(cnn_bn, val_loader, criterion)
sched.step()
if va > best_acc:
best_acc = va
improved = ""
if vl < best_loss:
best_loss = vl
epochs_no_improve = 0
improved = " *"
else:
epochs_no_improve += 1
print(f"Epoch {epoch:2d} | Train Acc {ta:5.2f}% | Val Acc {va:5.2f}%{improved}")
if epochs_no_improve >= 10:
print(f"Early stopping at epoch {epoch}")
break
test_loss, bn_acc = evaluate(cnn_bn, test_loader, criterion)
print(f"\nCNN+BN test accuracy: {bn_acc:.2f}%")
print(f"Improvement over PlainCNN: +{bn_acc - plain_acc:.1f}%")CNN+BN, 390,438 parameters
/tmp/ipykernel_26143/4188736977.py:4: FutureWarning: `torch.cuda.amp.GradScaler(args...)` is deprecated. Please use `torch.amp.GradScaler('cuda', args...)` instead.
scaler = GradScaler()
/tmp/ipykernel_26143/2983837481.py:7: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with autocast():
Epoch 1 | Train Acc 22.71% | Val Acc 24.17% *
/tmp/ipykernel_26143/2983837481.py:25: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with autocast():
Epoch 2 | Train Acc 29.17% | Val Acc 17.50%
Epoch 3 | Train Acc 35.21% | Val Acc 14.17%
Epoch 4 | Train Acc 36.88% | Val Acc 20.00%
Epoch 5 | Train Acc 38.75% | Val Acc 23.33% *
Epoch 6 | Train Acc 39.17% | Val Acc 19.17%
Epoch 7 | Train Acc 45.83% | Val Acc 20.83%
Epoch 8 | Train Acc 43.96% | Val Acc 27.50% *
Epoch 9 | Train Acc 46.67% | Val Acc 30.83% *
Epoch 10 | Train Acc 49.38% | Val Acc 29.17%
Epoch 11 | Train Acc 49.79% | Val Acc 35.83% *
Epoch 12 | Train Acc 48.96% | Val Acc 38.33% *
Epoch 13 | Train Acc 54.17% | Val Acc 33.33%
Epoch 14 | Train Acc 57.50% | Val Acc 39.17% *
Epoch 15 | Train Acc 57.50% | Val Acc 37.50%
Epoch 16 | Train Acc 61.46% | Val Acc 42.50% *
Epoch 17 | Train Acc 62.29% | Val Acc 43.33%
Epoch 18 | Train Acc 63.96% | Val Acc 38.33%
Epoch 19 | Train Acc 63.96% | Val Acc 41.67% *
Epoch 20 | Train Acc 63.75% | Val Acc 41.67%
CNN+BN test accuracy: 35.45%
Improvement over PlainCNN: +10.4%
Part 4: DeepResNet, Built from Scratch #
Our custom residual CNN. Each block applies Conv→BN→ReLU→Conv→BN, then adds the input back via a skip connection: output = F(x) + x. When dimensions change, we project the shortcut with a 1×1 convolution.
Residual Block #
class ResBlock(nn.Module):
def __init__(self, in_c, out_c, stride=1):
super().__init__()
self.conv1 = nn.Conv2d(in_c, out_c, 3, stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_c)
self.conv2 = nn.Conv2d(out_c, out_c, 3, 1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_c)
self.shortcut = nn.Sequential()
if stride != 1 or in_c != out_c:
self.shortcut = nn.Sequential(
nn.Conv2d(in_c, out_c, 1, stride, bias=False),
nn.BatchNorm2d(out_c),
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return outFull Model #
Three stages of residual blocks. Channels increase (64→128→256→512) while spatial size decreases (224→112→56→28). Global average pooling collapses the spatial dimensions, then dropout + a linear layer produces 6 class logits.
class DeepResNet(nn.Module):
def __init__(self, num_classes=NUM_CLASSES):
super().__init__()
self.conv1 = nn.Conv2d(3, 64, 3, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_block(64, 128, stride=2) # 224→112
self.layer2 = self._make_block(128, 256, stride=2) # 112→56
self.layer3 = self._make_block(256, 512, stride=2) # 56→28
self.pool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(512, num_classes)
def _make_block(self, in_c, out_c, stride):
return nn.Sequential(
ResBlock(in_c, out_c, stride),
ResBlock(out_c, out_c, 1),
)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.pool(x)
x = x.view(x.size(0), -1)
x = self.dropout(x)
x = self.fc(x)
return xresnet = DeepResNet()
print_architecture(resnet)Layer Output Shape Params
=========================================================================
conv1 [1, 64, 224, 224] 1,728
bn1 [1, 64, 224, 224] 128
layer1.0.conv1 [1, 128, 112, 112] 73,728
layer1.0.bn1 [1, 128, 112, 112] 256
layer1.0.conv2 [1, 128, 112, 112] 147,456
layer1.0.bn2 [1, 128, 112, 112] 256
layer1.0.shortcut.0 [1, 128, 112, 112] 8,192
layer1.0.shortcut.1 [1, 128, 112, 112] 256
layer1.0.shortcut [1, 128, 112, 112] 8,448
layer1.0 [1, 128, 112, 112] 230,144
layer1.1.conv1 [1, 128, 112, 112] 147,456
layer1.1.bn1 [1, 128, 112, 112] 256
layer1.1.conv2 [1, 128, 112, 112] 147,456
layer1.1.bn2 [1, 128, 112, 112] 256
layer1.1 [1, 128, 112, 112] 295,424
layer1 [1, 128, 112, 112] 525,568
layer2.0.conv1 [1, 256, 56, 56] 294,912
layer2.0.bn1 [1, 256, 56, 56] 512
layer2.0.conv2 [1, 256, 56, 56] 589,824
layer2.0.bn2 [1, 256, 56, 56] 512
layer2.0.shortcut.0 [1, 256, 56, 56] 32,768
layer2.0.shortcut.1 [1, 256, 56, 56] 512
layer2.0.shortcut [1, 256, 56, 56] 33,280
layer2.0 [1, 256, 56, 56] 919,040
layer2.1.conv1 [1, 256, 56, 56] 589,824
layer2.1.bn1 [1, 256, 56, 56] 512
layer2.1.conv2 [1, 256, 56, 56] 589,824
layer2.1.bn2 [1, 256, 56, 56] 512
layer2.1 [1, 256, 56, 56] 1,180,672
layer2 [1, 256, 56, 56] 2,099,712
layer3.0.conv1 [1, 512, 28, 28] 1,179,648
layer3.0.bn1 [1, 512, 28, 28] 1,024
layer3.0.conv2 [1, 512, 28, 28] 2,359,296
layer3.0.bn2 [1, 512, 28, 28] 1,024
layer3.0.shortcut.0 [1, 512, 28, 28] 131,072
layer3.0.shortcut.1 [1, 512, 28, 28] 1,024
layer3.0.shortcut [1, 512, 28, 28] 132,096
layer3.0 [1, 512, 28, 28] 3,673,088
layer3.1.conv1 [1, 512, 28, 28] 2,359,296
layer3.1.bn1 [1, 512, 28, 28] 1,024
layer3.1.conv2 [1, 512, 28, 28] 2,359,296
layer3.1.bn2 [1, 512, 28, 28] 1,024
layer3.1 [1, 512, 28, 28] 4,720,640
layer3 [1, 512, 28, 28] 8,393,728
pool [1, 512, 1, 1] 0
dropout [1, 512] 0
fc [1, 6] 3,078
=========================================================================
Total 11,023,942
11023942
Forward Pass, Shape Trace #
x = torch.randn(4, 3, IMG_SIZE, IMG_SIZE).to(device)
resnet = DeepResNet().to(device)
resnet.eval()
with torch.no_grad():
y = resnet.conv1(x)
print(f"After initial conv: {list(y.shape)}")
y = F.relu(resnet.bn1(y))
print(f"After BN + ReLU: {list(y.shape)}")
y = resnet.layer1(y)
print(f"After ResBlock 1: {list(y.shape)} (64→128, 224→112)")
y = resnet.layer2(y)
print(f"After ResBlock 2: {list(y.shape)} (128→256, 112→56)")
y = resnet.layer3(y)
print(f"After ResBlock 3: {list(y.shape)} (256→512, 56→28)")
y = resnet.pool(y)
print(f"After GlobalAvgPool: {list(y.shape)}")
y = y.view(y.size(0), -1)
print(f"After flatten: {list(y.shape)}")
y = resnet.dropout(y)
logits = resnet.fc(y)
print(f"After Linear: {list(logits.shape)} (6 class logits)")After initial conv: [4, 64, 224, 224]
After BN + ReLU: [4, 64, 224, 224]
After ResBlock 1: [4, 128, 112, 112] (64→128, 224→112)
After ResBlock 2: [4, 256, 56, 56] (128→256, 112→56)
After ResBlock 3: [4, 512, 28, 28] (256→512, 56→28)
After GlobalAvgPool: [4, 512, 1, 1]
After flatten: [4, 512]
After Linear: [4, 6] (6 class logits)
Training with Early Stopping #
Up to 20 epochs with early stopping (patience = 5 epochs on validation loss). The * marks when validation loss improved.
resnet = DeepResNet().to(device)
optimizer = torch.optim.AdamW(resnet.parameters(), lr=1e-3, weight_decay=1e-4)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=20)
scaler = GradScaler()
epochs = 30
patience = 5
history = {"train_loss": [], "train_acc": [], "val_loss": [], "val_acc": []}
best_acc = 0.0
best_loss = float("inf")
epochs_no_improve = 0
start = time.time()
for epoch in range(1, epochs + 1):
train_loss, train_acc = train_epoch(resnet, train_loader, criterion, optimizer, scaler)
val_loss, val_acc = evaluate(resnet, val_loader, criterion)
scheduler.step()
history["train_loss"].append(train_loss)
history["train_acc"].append(train_acc)
history["val_loss"].append(val_loss)
history["val_acc"].append(val_acc)
if val_acc > best_acc:
best_acc = val_acc
torch.save(resnet.state_dict(), "best_model.pt")
improved = ""
if val_loss < best_loss:
best_loss = val_loss
epochs_no_improve = 0
improved = " *"
else:
epochs_no_improve += 1
lr_now = optimizer.param_groups[0]["lr"]
print(f"Epoch {epoch:2d} | Train Loss {train_loss:.4f} Acc {train_acc:5.2f}% | "
f"Val Loss {val_loss:.4f} Acc {val_acc:5.2f}% | LR {lr_now:.2e}{improved}")
if epochs_no_improve >= patience:
print(f"\nEarly stopping at epoch {epoch}")
break
elapsed = time.time() - start
print(f"\nTraining: {elapsed/60:.1f} min | Best val loss: {best_loss:.4f} | Best val acc: {best_acc:.2f}%")/tmp/ipykernel_26143/577991586.py:4: FutureWarning: `torch.cuda.amp.GradScaler(args...)` is deprecated. Please use `torch.amp.GradScaler('cuda', args...)` instead.
scaler = GradScaler()
/tmp/ipykernel_26143/2983837481.py:7: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with autocast():
/tmp/ipykernel_26143/2983837481.py:25: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with autocast():
Epoch 1 | Train Loss 2.0111 Acc 18.75% | Val Loss 2.0020 Acc 15.00% | LR 9.94e-04 *
Epoch 2 | Train Loss 1.7888 Acc 22.29% | Val Loss 2.8056 Acc 13.33% | LR 9.76e-04
Epoch 3 | Train Loss 1.7315 Acc 25.21% | Val Loss 1.8803 Acc 17.50% | LR 9.46e-04 *
Epoch 4 | Train Loss 1.7058 Acc 30.21% | Val Loss 1.8006 Acc 19.17% | LR 9.05e-04 *
Epoch 5 | Train Loss 1.6532 Acc 33.33% | Val Loss 1.9391 Acc 17.50% | LR 8.54e-04
Epoch 6 | Train Loss 1.6192 Acc 33.96% | Val Loss 1.8679 Acc 22.50% | LR 7.94e-04
Epoch 7 | Train Loss 1.5996 Acc 38.75% | Val Loss 1.8615 Acc 23.33% | LR 7.27e-04
Epoch 8 | Train Loss 1.5763 Acc 33.33% | Val Loss 1.8387 Acc 27.50% | LR 6.55e-04
Epoch 9 | Train Loss 1.5284 Acc 40.62% | Val Loss 1.7853 Acc 30.00% | LR 5.78e-04 *
Epoch 10 | Train Loss 1.5364 Acc 38.96% | Val Loss 1.7848 Acc 29.17% | LR 5.00e-04 *
Epoch 11 | Train Loss 1.4826 Acc 40.83% | Val Loss 1.9205 Acc 31.67% | LR 4.22e-04
Epoch 12 | Train Loss 1.4651 Acc 44.58% | Val Loss 1.9092 Acc 28.33% | LR 3.45e-04
Epoch 13 | Train Loss 1.4363 Acc 45.21% | Val Loss 1.8635 Acc 24.17% | LR 2.73e-04
Epoch 14 | Train Loss 1.3766 Acc 45.42% | Val Loss 1.8488 Acc 30.83% | LR 2.06e-04
Epoch 15 | Train Loss 1.3403 Acc 47.71% | Val Loss 1.8700 Acc 30.83% | LR 1.46e-04
Early stopping at epoch 15
Training: 3.5 min | Best val loss: 1.7848 | Best val acc: 31.67%
Learning Curves #
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 4))
ax1.plot(history["train_loss"], label="Train Loss")
ax1.plot(history["val_loss"], label="Val Loss")
ax1.set_xlabel("Epoch")
ax1.set_ylabel("Loss")
ax1.set_title("Loss Curves")
ax1.legend()
ax1.grid(alpha=0.3)
ax2.plot(history["train_acc"], label="Train Acc")
ax2.plot(history["val_acc"], label="Val Acc")
ax2.set_xlabel("Epoch")
ax2.set_ylabel("Accuracy (%)")
ax2.set_title("Accuracy Curves")
ax2.legend()
ax2.grid(alpha=0.3)
plt.tight_layout()
plt.show()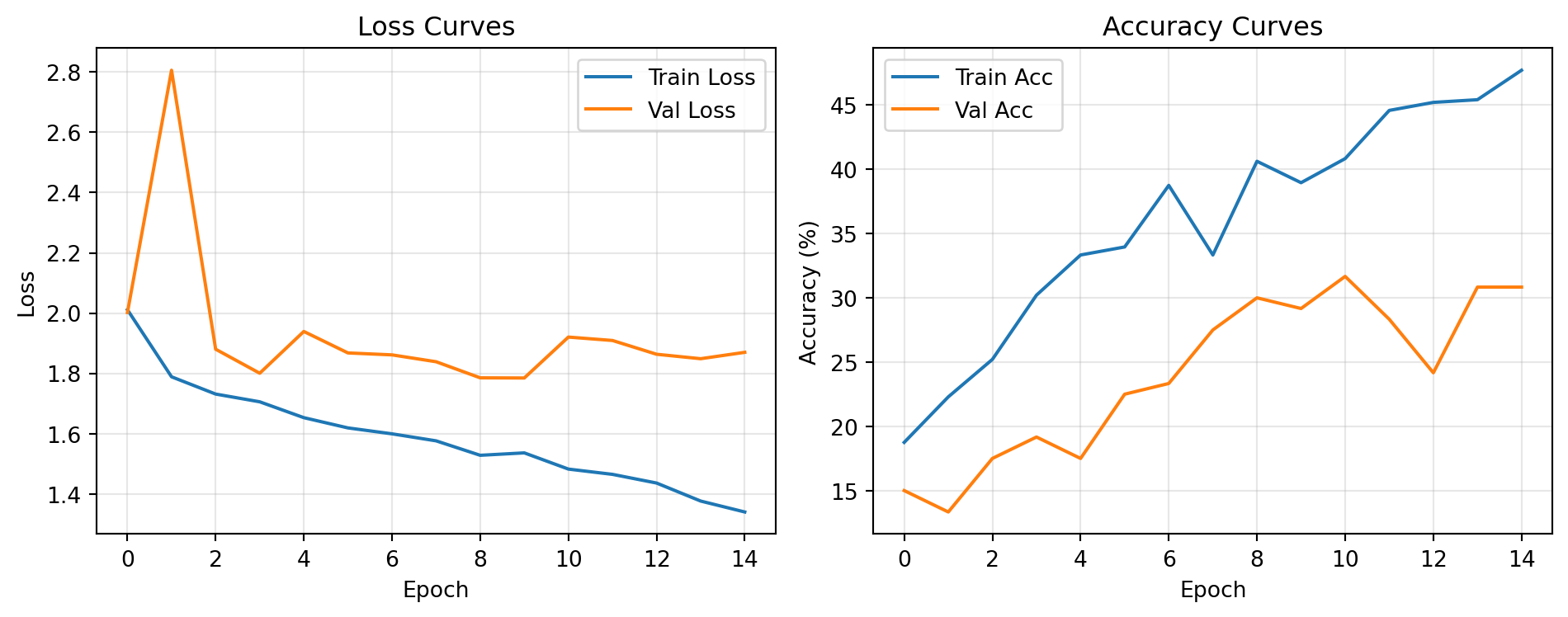
Test Evaluation #
resnet.load_state_dict(torch.load("best_model.pt", weights_only=True))
test_loss, resnet_acc = evaluate(resnet, test_loader, criterion)
print(f"DeepResNet Test Accuracy: {resnet_acc:.2f}%")/tmp/ipykernel_26143/2983837481.py:25: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with autocast():
DeepResNet Test Accuracy: 22.91%
all_preds, all_labels = [], []
resnet.eval()
with torch.no_grad():
for inputs, targets in test_loader:
inputs = inputs.to(device)
with autocast():
outputs = resnet(inputs)
_, preds = outputs.max(1)
all_preds.extend(preds.cpu().numpy())
all_labels.extend(targets.numpy())
print(classification_report(all_labels, all_preds, target_names=classes, digits=3))/tmp/ipykernel_26143/1124227186.py:6: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with autocast():
precision recall f1-score support
Abyssinian 0.531 0.265 0.354 98
american_bulldog 0.284 0.230 0.254 100
american_pit_bull 0.180 0.240 0.206 100
basset_hound 0.176 0.410 0.246 100
beagle 0.105 0.020 0.034 100
Bengal 0.253 0.210 0.230 100
accuracy 0.229 598
macro avg 0.255 0.229 0.221 598
weighted avg 0.254 0.229 0.220 598
Confusion Matrix #
cm = confusion_matrix(all_labels, all_preds)
cm_norm = cm.astype("float") / cm.sum(axis=1, keepdims=True)
fig, ax = plt.subplots(figsize=(7, 6))
im = ax.imshow(cm_norm, cmap="Blues")
ax.set_xticks(range(NUM_CLASSES))
ax.set_yticks(range(NUM_CLASSES))
ax.set_xticklabels(classes, rotation=30, ha="right", fontsize=8)
ax.set_yticklabels(classes, fontsize=8)
ax.set_xlabel("Predicted")
ax.set_ylabel("True")
ax.set_title("Confusion Matrix (Normalized)")
for i in range(NUM_CLASSES):
for j in range(NUM_CLASSES):
val = cm[i, j]
color = "white" if cm_norm[i, j] > 0.5 else "black"
ax.text(j, i, val, ha="center", va="center", color=color, fontsize=9)
plt.tight_layout()
plt.show()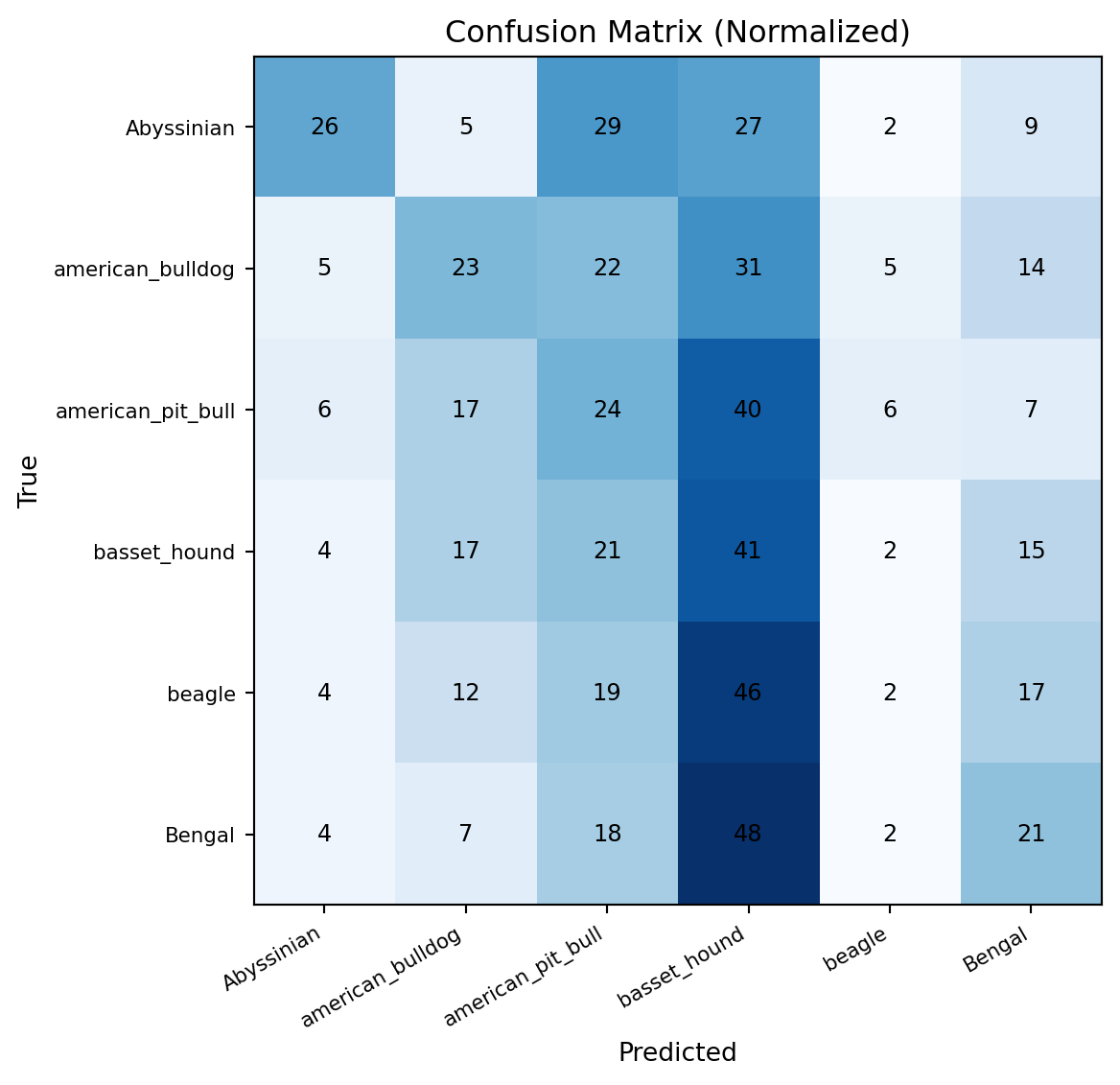
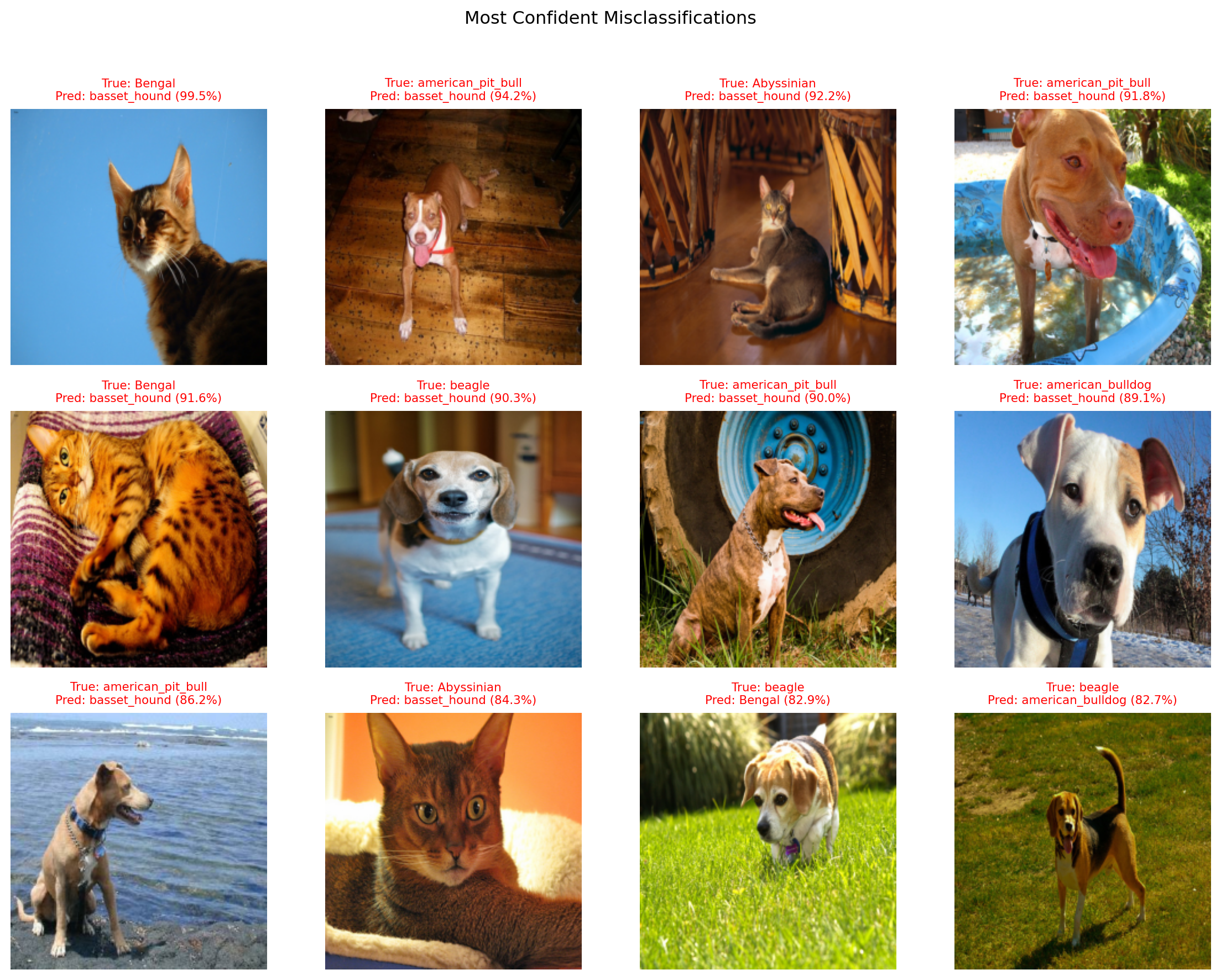
Misclassified Examples #
# Build raw test set without normalization for display
test_raw = torchvision.datasets.OxfordIIITPet(
root=DATA_DIR, split="test", target_types="category",
download=False, transform=transforms.Compose([
transforms.Resize((IMG_SIZE, IMG_SIZE)),
transforms.ToTensor(),
]),
)
test_raw_labels = [test_raw[i][1] for i in range(len(test_raw))]
test_raw_idx = [i for i, lbl in enumerate(test_raw_labels) if lbl < NUM_CLASSES]
test_raw = Subset(test_raw, test_raw_idx)
raw_loader = DataLoader(test_raw, batch_size=16, shuffle=False)
errors = []
idx = 0
with torch.no_grad():
for images, _ in raw_loader:
inp = transforms.Normalize(imagenet_mean, imagenet_std)(images).to(device)
with autocast():
outputs = resnet(inp)
probs = F.softmax(outputs, dim=1)
conf, preds = probs.max(1)
for i in range(len(preds)):
if preds[i].item() != all_labels[idx]:
errors.append((idx, images[i], all_labels[idx], preds[i].item(), conf[i].item()))
idx += 1
errors.sort(key=lambda e: e[4], reverse=True)
top_errors = errors[:12]
fig, axes = plt.subplots(3, 4, figsize=(12, 9))
for ax, (idx, img, true_lbl, pred_lbl, conf) in zip(axes.flat, top_errors):
ax.imshow(img.permute(1, 2, 0))
ax.set_title(f"True: {classes[true_lbl]}\nPred: {classes[pred_lbl]} ({conf:.1%})",
color="red", fontsize=8)
ax.axis("off")
plt.suptitle("Most Confident Misclassifications", fontsize=12, y=1.02)
plt.tight_layout()
plt.show()/tmp/ipykernel_26143/2984140589.py:19: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with autocast():
Visualizing Learned Filters #
filters = resnet.conv1.weight.data.cpu()
fig, axes = plt.subplots(8, 8, figsize=(8, 8))
for i, ax in enumerate(axes.flat):
if i < filters.size(0):
f = filters[i]
f = (f - f.min()) / (f.max() - f.min() + 1e-8)
ax.imshow(f.permute(1, 2, 0))
ax.axis("off")
plt.suptitle("First Layer Filters (64 × 3×3×3)", fontsize=14, y=1.01)
plt.tight_layout()
plt.show()
sample_img, sample_label = test_set[0]
sample_input = sample_img.unsqueeze(0).to(device)
with torch.no_grad():
conv1_out = F.relu(resnet.bn1(resnet.conv1(sample_input)))
activations = conv1_out[0].cpu()
fig, axes = plt.subplots(8, 8, figsize=(10, 10))
for i, ax in enumerate(axes.flat):
if i < activations.size(0):
ax.imshow(activations[i].numpy(), cmap="viridis")
ax.axis("off")
plt.suptitle(f"Activations, {classes[sample_label]} (64 channels)", fontsize=14, y=1.01)
plt.tight_layout()
plt.show()
Part 5: Transfer Learning with MobileNetV3-Small #
All models so far were built from scratch. Now we use a MobileNetV3-Small pretrained on ImageNet (1.4M images, 1000 classes). Its convolutional base already knows general visual features. At 224×224, the resolution matches what the model was trained on, all pretrained weights are preserved, no adaptation needed beyond replacing the classifier head.
from torchvision import models
transfer = models.mobilenet_v3_small(weights='IMAGENET1K_V1')
transfer.classifier[3] = nn.Linear(1024, NUM_CLASSES)
transfer = transfer.to(device)
print(f"MobileNetV3-Small, {sum(p.numel() for p in transfer.parameters()):,} params")
print("Pretrained backbone preserved, only classifier replaced")MobileNetV3-Small, 1,524,006 params
Pretrained backbone preserved, only classifier replaced
Feature Extraction #
Freeze the backbone, train only the new classifier head for 10 epochs.
for param in transfer.parameters():
param.requires_grad = False
transfer.classifier[3].weight.requires_grad = True
transfer.classifier[3].bias.requires_grad = True
opt = torch.optim.AdamW(transfer.classifier.parameters(), lr=1e-3)
sched = torch.optim.lr_scheduler.CosineAnnealingLR(opt, T_max=10)
scaler = GradScaler()
print("Feature extraction, training only the head (10 epochs)\n")
for epoch in range(1, 11):
tl, ta = train_epoch(transfer, train_loader, criterion, opt, scaler)
vl, va = evaluate(transfer, val_loader, criterion)
sched.step()
print(f"Epoch {epoch} | Train Acc {ta:5.2f}% | Val Acc {va:5.2f}%")
test_loss, transfer_acc = evaluate(transfer, test_loader, criterion)
print(f"\nFeature extraction test accuracy: {transfer_acc:.2f}%")Feature extraction, training only the head (10 epochs)
/tmp/ipykernel_26143/2988297993.py:8: FutureWarning: `torch.cuda.amp.GradScaler(args...)` is deprecated. Please use `torch.amp.GradScaler('cuda', args...)` instead.
scaler = GradScaler()
/tmp/ipykernel_26143/2983837481.py:7: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with autocast():
/tmp/ipykernel_26143/2983837481.py:25: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with autocast():
Epoch 1 | Train Acc 32.50% | Val Acc 51.67%
Epoch 2 | Train Acc 70.62% | Val Acc 67.50%
Epoch 3 | Train Acc 79.79% | Val Acc 74.17%
Epoch 4 | Train Acc 88.33% | Val Acc 75.83%
Epoch 5 | Train Acc 89.17% | Val Acc 79.17%
Epoch 6 | Train Acc 89.58% | Val Acc 82.50%
Epoch 7 | Train Acc 90.21% | Val Acc 84.17%
Epoch 8 | Train Acc 90.00% | Val Acc 86.67%
Epoch 9 | Train Acc 91.25% | Val Acc 86.67%
Epoch 10 | Train Acc 91.04% | Val Acc 85.00%
Feature extraction test accuracy: 83.95%
Fine-Tuning #
Unfreeze the last few blocks and train with a low learning rate for 5 epochs.
for param in transfer.parameters():
param.requires_grad = True
opt = torch.optim.AdamW([
{'params': transfer.features[-5:].parameters(), 'lr': 1e-5},
{'params': transfer.classifier.parameters(), 'lr': 1e-3},
], weight_decay=1e-4)
sched = torch.optim.lr_scheduler.CosineAnnealingLR(opt, T_max=3)
print("Fine-tuning, unfreezing last 5 blocks (5 epochs)\n")
for epoch in range(1, 6):
tl, ta = train_epoch(transfer, train_loader, criterion, opt, scaler)
vl, va = evaluate(transfer, val_loader, criterion)
sched.step()
print(f"Epoch {epoch} | Train Acc {ta:5.2f}% | Val Acc {va:5.2f}%")
test_loss, finetune_acc = evaluate(transfer, test_loader, criterion)
print(f"\nFine-tuned test accuracy: {finetune_acc:.2f}%")Fine-tuning, unfreezing last 5 blocks (5 epochs)
/tmp/ipykernel_26143/2983837481.py:7: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with autocast():
Epoch 1 | Train Acc 87.08% | Val Acc 85.00%
/tmp/ipykernel_26143/2983837481.py:25: FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.
with autocast():
Epoch 2 | Train Acc 92.50% | Val Acc 85.00%
Epoch 3 | Train Acc 95.42% | Val Acc 85.83%
Epoch 4 | Train Acc 96.46% | Val Acc 84.17%
Epoch 5 | Train Acc 96.25% | Val Acc 90.00%
Fine-tuned test accuracy: 84.45%
Summary #
We started with a bare convolutional stack and progressively added architectural improvements, then leveraged pretrained weights, all on the same Oxford-IIIT Pet dataset at native 224×224 resolution.
models = ["PlainCNN", "+\nDropout", "+\nBatchNorm",
"DeepResNet\n(from scratch)", "Transfer\n(feature ext.)", "Transfer\n(fine-tuned)"]
accs = [plain_acc, drop_acc, bn_acc, resnet_acc, transfer_acc, finetune_acc]
colors = ["#e74c3c", "#e67e22", "#f39c12", "#2ecc71", "#3498db", "#9b59b6"]
fig, ax = plt.subplots(figsize=(10, 5))
bars = ax.bar(models, accs, color=colors)
ax.bar_label(bars, fmt="%.1f%%", fontsize=11, fontweight="bold")
ax.set_ylabel("Test Accuracy (%)")
ax.set_ylim(0, 100)
ax.set_title("From Scratch to Transfer Learning, Accuracy Progression")
plt.tight_layout()
plt.show()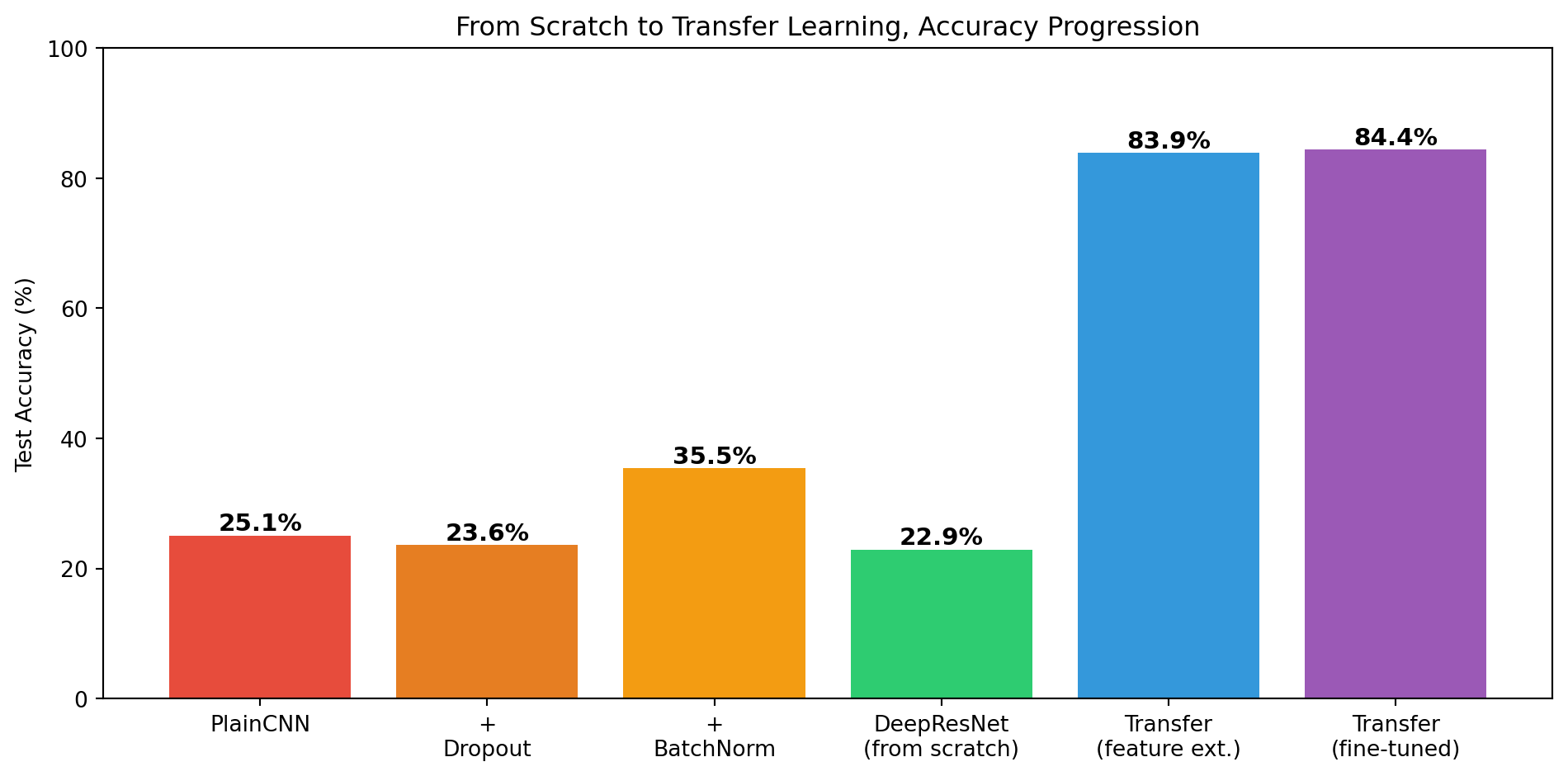
Key takeaways:
-
Dropout is the simplest regularization, zero cost in parameters, consistently improves over the bare baseline.
-
BatchNorm gives a larger accuracy boost by stabilizing training across deeper networks.
-
Residual connections push accuracy further with skip connections that let gradients flow unimpeded.
-
Transfer learning with a pretrained MobileNetV3-Small reaches strong accuracy when inputs match the model’s native 224×224 resolution.
-
Fine-tuning squeezes out additional gains by adapting high-level features to the specific pet breeds.